V dnešnom digitálnom svete sa dáta stali jednou z najcennejších komodít. Dáta sú všadeprítomné a stávajú sa hybnou silou inovácií vo všetkých oblastiach ľudskej činnosti. Ich efektívne využitie však vyžaduje porozumenie ich štruktúre a spracovaniu - čo nás privádza k dátovým štruktúram. Predstavme si knižnicu bez akéhokoľvek systému usporiadania kníh - chaos, v ktorom je takmer nemožné nájsť, čo hľadáme. Tieto štruktúry, ktoré sú pre nás používateľov neviditeľnou architektúrou, sú zodpovedné za správnu kategorizáciu dát, uloženie a spracovanie takým spôsobom, aby napr. V tomto článku sa ponoríme do fascinujúceho sveta dátových štruktúr. Povieme si o tých základných, ako sú polia a zoznamy. Od tých základných, ako sú polia a zoznamy, až po pokročilé, ako hashovacie tabuľky alebo binárne stromy, ukážeme si, ako každá z nich hrá kľúčovú rolu v riešení rôznych výpočtových problémov.
Nepochopením kľúčových vlastností, silných a slabých stránok tej ktorej dátovej štruktúry a ich nevhodným, neefektívnym použitím strácame nielen drahocenný čas spracovania dát, ale aj plytváme hardvérovými prostriedkami. Ako všetci vieme, čas sú peniaze a napr. Dáta nie sú len bezvýznamne binárne čísla alebo text zložený z podivných ASCII znakov - sú základom nášho života. Dáta predstavujú základné stavebné kamene informácií. Sú to obyčajné fakty, čísla, texty, symboly, zvuky či obrazy, ktoré nemajú bez kontextu žiadny konkrétny význam. Surovosť: Dáta sú neinterpretované. Potenciál pre informáciu: Keď sa dáta spracujú, analyzujú alebo umiestnia do kontextu, premieňajú sa na informácie. Dáta tvoria základ všetkých rozhodnutí v modernom svete. Firmy ich využívajú na analýzu trhu, vedci na výskum, lekári na diagnostiku a liečbu a vlády na plánovanie rozpočtov. Umelá inteligencia (AI) ako ju dnes poznáme by bez nich nikdy nevznikla.
Čo sú dátové štruktúry a prečo sú dôležité?
Dátové štruktúry predstavujú spôsob organizácie, uchovávania a spracovania dát tak, aby sa dali efektívne používať v počítačových programoch. Poskytujú dátam určitú formu a určujú, ako budú dáta usporiadané, ale aj ako s nimi bude možné manipulovať. Vždy sa pri návrhu dátovej štruktúry, alebo pri výbere nejakej existujúcej snažíme optimalizovať rýchlosť operácií ako vyhľadávanie dát, ich načítanie a zápis. Sekundárne treba pamätať na to, že efektívne dátové štruktúry by mali minimalizovať pamäťovú náročnosť. To zahŕňa nielen priestor pre uloženie dát, ale aj pomocných štruktúr, indexov alebo metadát, ktoré pomáhajú pri rýchlejšom vyhľadávaní práve požadovaných informácií. Implementácia dátovej štruktúry by mala byť pre dané dáta, čo najjednoduchšia, aby sa eliminovalo riziko chýb.
Lineárne a nelineárne dátové štruktúry
- V lineárnej dátovej štruktúre sú všetky prvky usporiadané v lineárnom alebo sekvenčnom poradí.
- V nelineárnej dátovej štruktúre sú elementy usporiadané hierarchicky alebo do viacúrovňovej komplexnej dátovej štruktúry.
Triedenie (sort)
Prvky dátovej štruktúry možno triediť buď vzostupne alebo zostupne.
Abstraktný dátový typ vs. Dátová štruktúra
ADT hovorí, čo sa má urobiť, a dátová štruktúra hovorí, ako sa to má urobiť. Inými slovami, môžeme povedať, že ADT nám poskytuje návrh, zatiaľ čo dátová štruktúra poskytuje implementačnú časť. V konkrétnom ADT môžu byť implementované rôzne dátové štruktúry. Napr. ADT zásobník môže na dátovej úrovni využívať dátovú štruktúru pole, alebo spájaný zoznam (linked list).
Základné dátové štruktúry
Polia
V programovaní sú polia jednou z najnákladnejších a najpoužívanejších dátových štruktúr. Ukladajú prvky v súvislom bloku pamäte, pričom každý prvok je prístupný pomocou číselného indexu.
- Pevná veľkosť: Po deklarovaní poľa je jeho veľkosť fixná a nemožno ju počas behu meniť. Preto potrebujeme dopredu vedieť, koľko prvkové pole treba vytvoriť.
- Viacrozmerné polia (Multidimensional arrays): Polia, ktoré obsahujú jedno alebo viac polí ako svoje prvky. To umožňuje vytvárať dátovú reprezentáciu vo viacerých dimenziách. Napr.
- Pamäťová efektívnosť: Je veľmi efektívne na ukladanie veľkého počtu prvkov za sebou.
- Implementácia iných dátových štruktúr: Pole je základná štruktúra pre zložitejšie dátové štruktúry, ako sú haldy, hašovacie tabuľky a dynamické polia (napr.
Spájaný zoznam (Linked List)
Spájaný zoznam je základná dátová štruktúra, ktorá sa odlišuje od poľa svojou dynamickou povahou a flexibilitou. Na rozdiel od polí, ktoré vyžadujú súvislý blok pamäte, zoznam pozostáva z uzlov rozptýlených v pamäti, pričom každý uzol obsahuje hodnotu a referenciu (ukazovateľ) na ďalší uzol.
- Jednosmerný zoznam (Singly listed list): Každý uzol obsahuje hodnotu a odkaz na ďalší uzol. Predstav si správu histórie v prehliadači. Každý navštívený web je uložený ako uzol v zozname. Keď sa vrátiš späť na predchádzajúcu stránku, jednoducho sa pohneš na predchádzajúci uzol, čo je ideálny príklad, kde zoznam exceluje.
Zásobník (Stack)
Zásobník je jednou zo základných dátových štruktúr, ktorá funguje na princípe „posledný dovnútra, prvý von“ (LIFO - Last In, First Out). Predstavme si ho ako sadu tanierov uložených na sebe - nový tanier pridáme vždy navrch a pri odoberaní vždy siahneme po tom vrchnom.
- Správa funkčných volaní: Zásobníky sa používajú na správu volaní funkcií v programoch. Predstavme si editor textu s funkciou naspäť. Každá zmena, ktorú vykonáme, sa pridá na zásobník. Zásobníky sú síce špecifické svojou jednoduchosťou a obmedzeniami, no práve vďaka týmto vlastnostiam sú nenahraditeľné v mnohých aplikáciách a algoritmoch, kde treba presne zachovať poradie vykonávania operácií.
Fronta (Queue)
Fronta je základná dátová štruktúra, ktorá funguje na princípe „prvý dovnútra, prvý von“ (FIFO - First In, First Out). Predstaviť si ju môžeme ako poradie objednávok čakajúcich na vybavenie - tá, ktorá prišla ako prvá bude aj ako prvá vybavená.
- Efektivita: Pridávanie a odoberanie prvkov je časovo efektívne, s časovou zložitosťou O(1) v prípade správnej implementácie (napr. Predstavme si pokladňu v supermarkete. Každý zákazník, ktorý príde, sa zaradí na koniec radu (enqueue). Pokladník obslúži vždy zákazníka na začiatku radu (dequeue). Fronty sú užitočné všade tam, kde je potrebné efektívne spracovávať úlohy alebo údaje v poradí ich príchodu.
Pokročilé dátové štruktúry
Strom
Strom je základná nelineárna dátová štruktúra, ktorá organizuje dáta hierarchicky. Skladá sa z uzlov, kde každý uzol má jeden nadradený uzol - rodiča (okrem koreňového uzla) a môže mať nula alebo viacero podriadených uzlov - potomkov.

- Uzly a hrany: Každý uzol obsahuje dáta a odkazy na svoje podriadené uzly. Predstavte si rodokmeň - koreň stromu predstavuje najstaršieho predka a uzly nižšie znázorňujú jeho potomkov. Stromy sú jednou z najdôležitejších dátových štruktúr v informatike.
Graf
Graf je nelineárna dátová štruktúra, ktorá reprezentuje objekty (uzly, nazývané vrcholy) a vzťahy medzi nimi (nazývané hrany). Existujú rôzne druhy grafov, na obrázku vľavo neorientovaný, vpravo orientovaný.
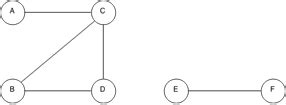
- Orientácia: Graf môže byť orientovaný (smerované hrany, napr. jednosmerná ulica) alebo neorientovaný (bez smerovania, napr. Predstavme si mestskú dopravnú sieť. Každé miesto (zastávka) je vrchol a spojenie medzi zastávkami je hrana. Grafy sú nenahraditeľné pri riešení komplexných problémov, kde je kľúčové pochopiť a vedieť analyzovať vzťahy medzi objektmi.
Hašovacia tabuľka (Hash Table)
Hašovacia tabuľka je dátová štruktúra, ktorá implementuje asociatívne pole, v ktorom sa hodnoty (dáta) ukladajú a vyhľadávajú na základe unikátneho kľúča.
- Hašovacia funkcia: Kľúč sa pomocou tejto funkcie prevádza na index v príslušnom poli.
- Kolízie: Ak dva rôzne kľúče generujú rovnaký index, dochádza ku kolízii, ktorá sa rieši špecifickými technikami (napr.
- Otvorené adresovanie: Ak nastane kolízia, hľadá sa iný voľný slot podľa určitého vzoru (napr. Predstavme si telefónny zoznam, v ktorom chceme rýchlo vyhľadať číslo osoby na základe jej mena. Meno osoby slúži ako kľúč, ktorý sa pomocou hašovacej funkcie prevedie na index. Hašovacie tabuľky sú výkonnou a efektívnou štruktúrou pre širokú škálu aplikácií, kde je prioritou rýchly prístup k údajom.
Strom Rodičovský Uzol v Huffmanovom Kódovaní
V kontexte Huffmanovho kódovania, rodičovský uzol zohráva kľúčovú rolu pri vytváraní optimálneho kódovacieho stromu. Každý rodičovský uzol reprezentuje spojenie dvoch uzlov s najnižšou pravdepodobnosťou výskytu, čím sa zabezpečuje, že najčastejšie znaky budú mať kratšie kódové slová.
Pri tvorbe Huffmanovho kódu budeme vytvárať binárny strom, čo bude vlastne kódovací strom Huffmanovho kódu. Na začiatku máme pre každý znak abecedy jeden uzol stromu (list). Opakovane vyberáme dva uzly s najmenšou pravdepodobnosťou výskytu. Vytvoríme nový uzol (rodičovský uzol), ktorý bude mať tieto dva uzly ako svojich potomkov. Pravdepodobnosť tohto nového uzla bude súčtom pravdepodobností jeho potomkov. Tento nový uzol vložíme späť do množiny uzlov. Tento proces opakujeme, kým nám nezostane len jeden uzol - koreň stromu.

Princíp fungovania
- Prípravná fáza: Pre každý znak abecedy vytvoríme listový uzol stromu s jeho pravdepodobnosťou výskytu.
- Konštrukcia stromu: Opakovane spájame dva uzly s najnižšími pravdepodobnosťami do nového rodičovského uzla, ktorého pravdepodobnosť je súčtom pravdepodobností jeho potomkov. Tento proces opakujeme, kým nezostane iba jeden koreňový uzol.
- Priradenie kódových slov: Prechádzame stromom od koreňa k listom. Každej hrane vedúcej k ľavému potomkovi priradíme bit "0" a každej hrane vedúcej k pravému potomkovi priradíme bit "1". Kódové slovo pre daný znak získame spojením bitov na ceste od koreňa k listu reprezentujúcemu daný znak.
Implementácia v C++
Nasledujúci kód v C++ demonštruje základné kroky Huffmanovho kódovania:
#include#include #include #include #include
Dôležité aspekty implementácie
- Prioritná fronta: Použitie prioritnej fronty (min-heap) je kľúčové pre efektívne vyhľadávanie dvoch uzlov s najmenšou pravdepodobnosťou.
- Dynamická alokácia pamäte: Pri vytváraní uzlov stromu je potrebné dynamicky alokovať pamäť pomocou `new`. Nezabudnite na uvoľnenie pamäte po skončení programu, aby nedošlo k memory leakom. V ukážke je použitý destruktor `~TUzol` na rekurzívne uvoľnenie pamäte.
- Rekurzia: Rekurzívna funkcia `zapis_kodove_slova` elegantne prechádza stromom a priraďuje kódové slová.
Ďalšie dátové štruktúry spomenuté v kontexte
- Binárny strom: Strom, ktorý spĺňa nasledovnú podmienku (každý rodičovský uzol je väčší alebo menší ako jeho potomkovia).
- Trie: Stromová tabuľková štruktúra optimalizovaná na vyhľadávanie reťazcov, kde každý uzol reprezentuje časť kľúča.
- Stromy pre intervaly a rozsahy: Strom navrhnutý na efektívne riešenie problémov spojených s intervalmi a rozsahmi údajov.
- Segmentový strom: Efektívna štruktúra na aktualizáciu a vyhľadávanie súčtov v postupnostiach.
- K-d strom: Špecializovaný strom na organizáciu bodov v K-rozmernom priestore.
- Súkený strom (Suffix Tree): Reprezentuje všetky sufixy daného reťazca.
- Maticové tabuľky: Dvojrozmerné alebo viacrozmerné polia, ktoré ukladajú dáta v riadkoch a stĺpcoch. Používa sa napr.
- Adjacency Matrix: Dvojrozmerná matica, kde riadky a stĺpce reprezentujú vrcholy grafu a hodnoty v matici indikujú existenciu hrán medzi vrcholmi.
- Adjacency List: Zoznam, kde každý vrchol grafu obsahuje zoznam všetkých svojich susedných vrcholov.
- Sparse Matrix: Štruktúra na ukladanie matíc s väčšinou nulových hodnôt, kde sa ukladajú iba nenulové hodnoty a ich polohy.
Aplikácie Huffmanovho kódovania
Huffmanovo kódovanie sa používa v mnohých aplikáciách, kde je dôležitá kompresia dát:
- Kompresné formáty: JPEG, PNG, GZIP, ZIP
- Prenos dát: Fax, modem
- Archivácia dát: Ukladanie dát s obmedzeným priestorom
Dátové štruktúry sú neodmysliteľnou súčasťou programovania, pretože poskytujú spôsob ako efektívne organizovať, spracovať a manipulovať údaje. Ich správny výber a implementácia môže významne ovplyvniť výkon a efektivitu softvéru.
tags: #strom #rodicovsky #uzol